
“대량의 데이터 집합으로부터 유용한 정보를 추출하는 것.(Hand et al., 2001)”
“데이터 마이닝이란 의미있는 패턴과 규칙을 발견하기 위해서 자동화되거나 반 자동화된 도구를 이용하여 대량의 데이터를 탐색하고 분석하는 과정이다.(Berry and Linoff, 1997, 2000).”
“데이터마이닝은 통계 및 수학적 기술뿐만 아니라 패턴인식 기술들을 이용하여 데이터 저장소에 저장된 대용량의 데이터를 조사함으로써 의미있는 새로운 상관관계, 패턴, 추세 등을 발견하는 과정이다.(Gartner Group, 2004).”
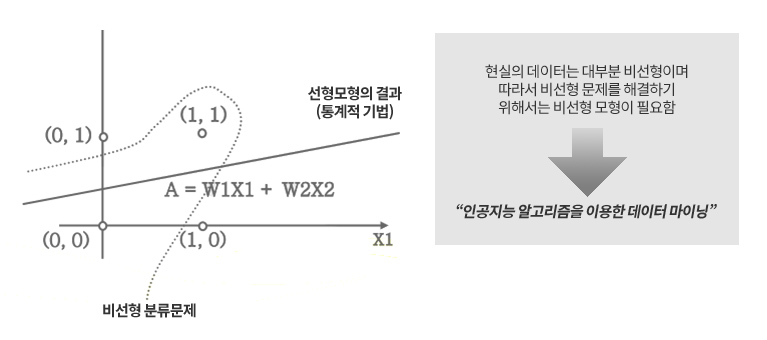
데이터마이닝은 통계학과 기계학습(machine learning, 인공지능)으로 알려진 두 학문분야를 모두 포함한다. 데이터를 탐색하고 모델을 구축하는 다양한 기법들은 통계학 분야에서 오랫동안 존재해 왔다. 예를 들어 여기에는 선형 회귀분석, 로지스틱 회귀분석, 판별분석, 주성분분석 등이 있다. 그러나, 충분한 데이터와 계산능력을 가진 데이터마이닝의 응용분야에서는 이러한 고전적인 통계학의 핵심원리(계산이 어렵고 데이터가 희소하다는 것)가 적용되지 않는다. 이러한 이유로 해서 데이터마이닝은 “규모와 속도의 통계학(statistics at scale and speed: Pregibon, 1999)” 또는 이를 좀더 확장한 개념으로서 “규모, 속도 및 단순성의 통계학(statistics at scale, speed, and simplicity)”으로 설명된다.
기존의 통계적 분석 도구나 OLAP은 세워진 모형이나 가설에 의거해 이를 검증하거나 요약 보고하는 데 초점을 맞추고 있는 데 반면, 데이터 마이닝의 목적은 궁극적으로 예측에 초점을 둔다. 데이터 마이닝에 사용되는 인공 지능 기법은 그 어떠한 기법보다 모형의 예측 성과를 높이는 데 가장 우수한 기법이다.
예측모형은 결과값이 알려진 다변량 자료를 이용하여 모형을 구축하고, 이를 통해 새로운 자료에 대해 결과값에 대한 예측 또는 분류를 수행하는 방법이다. 결과값이 범주형인 경우에는 새로운 자료에 대한 분류(classification)가 주목적이며, 결과값이 연속형인 경우에는 예측(prediction)이 주목적이라 할 수 있다. 따라서 예측과 분류는 유사한 의미로 사용되며 통칭하여 예측모형으로 부르기로 한다. 대표적인 예측모형으로는 로지스틱 회귀, 의사결정나무, 판별분석, 인접이웃분류, 베이즈분류, 신경망, 서포트벡터머신과 이들 예측모형(분류기)들을 결합한 앙상블 모형 등이 있다. 기계학습 분야에서는, 결과값이 알려진 상황에서의 학습모형인, 예측모형을 지도학습 (supervised learning)이라 부른다. 예측모형은 목표마케팅, 성과예측, 의학진단, 사기검출, 제조 등 다양한 분야에 이용되고 있다.
한편, 예측모형과는 달리 별도의 결과값을 요구하지 않는 자료에 대한 분석을 비지도학습 (unsupervised learning)이라 한다. 예를 들어, 군집분석은 데이터의 개체들 간의 유사성에 기반하여 전체 개체를 몇 개의 군집으로 나누는 방법으로 사용된다. 모형 구축시에 결과값이 주어져 있지 않음으로 오차(또는 보상 신호) 의 개념이 사용되지 않는다. 대표적인 비지도 학습에는 k-평균군집, 계층적군집, 혼합분포군집을 비롯한 다양한 군집분석과 주성분분석, 독립성분분석 등이 포함된다.