
대용량의 웹 사이트 데이터를 빠르게 수집할 수 있습니다.

데이터 크롤링(Data Crawling)은 주어진 인터넷 주소(URL)에 접근해 다른 인터넷 주소를 찾아내고, 찾은 인터넷 주소에서 또 다른 인터넷 주소를 찾는 작업을 반복하며 얻은 데이터들을 데이터베이스(DB)에 저장하는 것을 뜻한다.
최근엔 위 개념에서 확장하여 해당 웹사이트의 데이터 자체를 추출하여 특정형태(csv, json, xml)로 저장하는 데이터 스크래핑(Data Scraping)의 의미로도 사용된다.
크롤러(Crawler)는 웹 크롤링을 위한 소프트웨어다. 주어진 웹에서 정보를 추출한다는 목적은 같지만, 소프트웨어 사용 난이도와 데이터의 양, 웹 페이지의 성격 등에 따라 적합한 소프트웨어를 사용하는 것이 좋다. 크롤러는 아래의 그림과 같이 크게 3가지의 소프트웨어가 대표적이다.

각각의 크롤러는 사용 난이도, 동적 페이지 수집 가능여부에 따라 구분되어 사용된다. 가장 접근이 쉬운 것은 BeautifulSuop이며, Selenium, Scrapy 순으로 사용 난이도가 높아진다. BeautifulSuop 은 사용이 쉽지만 동적 페이지를 수집하는데 제한이 있기 때문에 다른 크롤러보다 확장성이 떨어진다. Selenuim은 크롤링 뿐만 아니라 평소에 반복적으로 하고 있는 웹 상의 업무를 자동화 할 수 있어 주로 사용되는 크롤러이다. 이에 자신이 정보를 수집할 웹 페이지에 특성을 보고 어느 소프트웨어를 사용할 것인지 결정해야 한다.
분석 방법 및 분석 방향은 데이터 형태에 따라 나뉘어진다.
| 데이터의 형태 | 분석 방법 |
|---|---|
| 텍스트 데이터 | 키워드 빈도분석, 워드클라우드, 감정분석 등 |
| 이미지 데이터 | 이미지 분류를 위한 머신러닝, 딥러닝(CNN, LSTM 등) |
| 숫자 데이터 | 데이터 EDA, 회귀분석, 분산분석 등 모든 수치 자료 분석 |
웹 사이트에 있는 문자, 숫자, 이미지 등의 모든 형태의 데이터를 수집 가능하기 때문에 모든 산업군에서 데이터 크롤링이 사용 가능하며, 데이터 분석팀 뿐만 아니라 마케팅이나 고객 관리팀과 같은 곳에서도 새로운 인사이트를 찾기 위해 사용된다.
특히 크롤러를 이용하여 특정 제품에 관한 가격정보를 수집하고 자사 제품의 가격 경쟁력을 타사 제품과 비교 할 수 있으며, 리뷰데이터(text data)를 수집하여 제품의 후기를 정리하고 피드백 하며 문제점을 개선한다. 또한 특정 분야의 이슈 파악을 위한 뉴스정보를 수집하여 새로운 시장이나 제품의 등장을 빠르게 파악 가능하다. 최근에는 이미지를 수집하여 머신러닝이나 딥러닝 학습에 필요한 Training Data 로 사용되기도 한다.
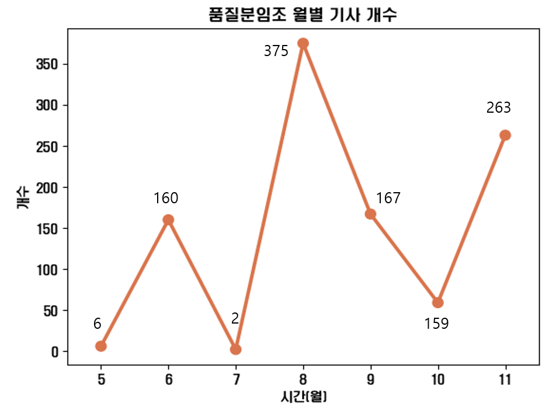
데이터 크롤링의 한 예시로 품질/제조 분야의 뉴스를 수집하고 기간별 기사의 개수를 이용하여 워드클라우드를 통해 도식화 해 보았다. 기간별로 데이터를 수집한다면 시간의 흐름에 따라 어떤 단어들이 얼마나 언급 되는지 알 수 있으며, 최신 품질/제조분야의 키워드를 파악 할 수 있다.

왼쪽 그림은 품질/제조분야의 일부 기사들의 본문을 크롤링 하여 워드클라우드로 나타낸 것이다. 기사에 자주 등장하는 단어는 크게, 적게 등장하는 단어는 크기를 작게하여 중요도를 나타낸다. 이 워드클라우드는 스마트 팩토리라는 단어가 가장 많이 언급된 것을 알 수 있으며 스마트, 품질분임조, 로봇과 같은 단어도 품질/제조분야에서 주목 받고 있다는 것을 알 수 있다.
또한 기간별로 특정 단어가 포함되어있는 기사의 수를 파악하여 시간 별로 그래프로 표현하는 방법도 있을 수 있다. ‘품질 분임조’라는 단어 대신 자사 제품의 단어에 대해 크롤링을 진행한다면, 자사 제품에 대한 언급량을 파악하여 마케팅 효과의 성공의 정도를 파악하는 것도 가능하다.
크롤링은 데이터 분석 단계 중 데이터 수집단계에 해당하므로, 분석에 맞는 데이터만 수집 가능하다면 그 활용성이 무궁무진하다.
자세한 내용 및 무료 상담을 위해 온라인 상담 요청서를 작성해 주시기 바랍니다. 담당자가 확인 후 빠른 시간 내에 연락 드리겠습니다.
온라인 상담 요청하기